
Di Mirko Lagonegro, ceo e cofondatore di Digital MDE
Ampliando il portafoglio di soluzioni e servizi della mia azienda, negli ultimi giorni ho approfondito la conoscenza di due tecnologie che, sebbene con finalità differenti, credo diverranno molto rilevanti per un ulteriore sviluppo del contesto audio. Sono sempre stato interessato all’innovazione tecnologica – a metà anni ’90 promuovevo l’uso dei primi sistemi di automazione per la messa in onda presso le emittenti radiofoniche – ma non sono mai stato un cultore dello strumento in sé. Ero più interessato a come utilizzarlo per poter fare cose nuove o per trovare nuovi modi di fare le cose.
È il caso di Dolby Atmos, che stiamo impiegando per una nostra produzione: consente di posizionare un suono agendo non solo sull’asse orizzontale, sulla “larghezza” dell’immagine sonora (sinistra – destra, come avviene nella comune stereofonia), ma su tre: larghezza, altezza e profondità. In pratica, posso simulare un suono di passi in modo che l’ascoltatore lo percepisca provenire alle proprie spalle, magari iniziando dall’alto e per poi abbassarlo d’altezza, come se qualcuno stesse scendendo le scale(qui un video con cui rendersi conto delle sue caratteristiche). La cosa pazzesca è che Dolby Atmos funziona con le normali cuffiette che tutti noi usiamo, rendendo disponibile un’esperienza sonora paragonabile a quella offerta in un cinema dotato di un impianto composto da decine di altoparlanti senza dover acquistare nulla.
Non è alla portata di tutti, si tratta di una tecnologia che richiede grandi investimenti, certificazioni specifiche e parecchio training per poter essere usata al massimo delle potenzialità. Ma applicata al podcast potrà offrire ai creativi la possibilità di immaginare – e realizzare – contenuti capaci di creare un’esperienza davvero immersiva e di grandissimo impatto, a beneficio degli ascoltatori e dei Brand che vorranno associarsi a storie pensate e prodotte con questo strumento.
Altro fronte in continuo sviluppo è quello dei software “text to speech”, soluzioni che trasformano un testo scritto in un file audio, qualsiasi sia la lingua di cui si dispone in origine. Non è una novità delle ultime ore, da anni Google, Amazon e Microsoft ci lavorano intensamente e sono più di una le soluzioni disponibili, tutto sommato economicamente, sul mercato. Quello che mi pare essere molto interessante da osservare è l’ambito di utilizzo, la funzione che questa tecnologia può abilitare.
Chiarisco: per quanto questi strumenti siano sempre più evoluti e raffinati, al punto che oggi può non risultare immediato distinguerli da una voce umana, non credo potranno mai essere usati per fare un podcast, se usando questo termine ci riferiamo all’audio storytelling, ad un contenuto audio di tipo narrativo (anche se, temo, qualcuno ci proverà…).
La questione secondo me rilevante è che ci sono tanti contesti in cui il linguaggio audio può essere efficacemente implementato, ambienti in cui la valenza “funzionale” dell’audio – non posso guardare ma posso ascoltare – rappresenta già di per sé un notevole valore aggiunto. Siglando una partnership esclusiva con uno dei leader mondiali di questo comparto, Trinity Audio, abbiamo appreso che la già ampia schiera di publisher mondiali che l’ha implementata per rendere i propri contenuti testuali disponibili per le orecchie, oltreché per gli occhi, ha visto i principali indicatori di utilizzo crescere rapidamente e in modo significativo.
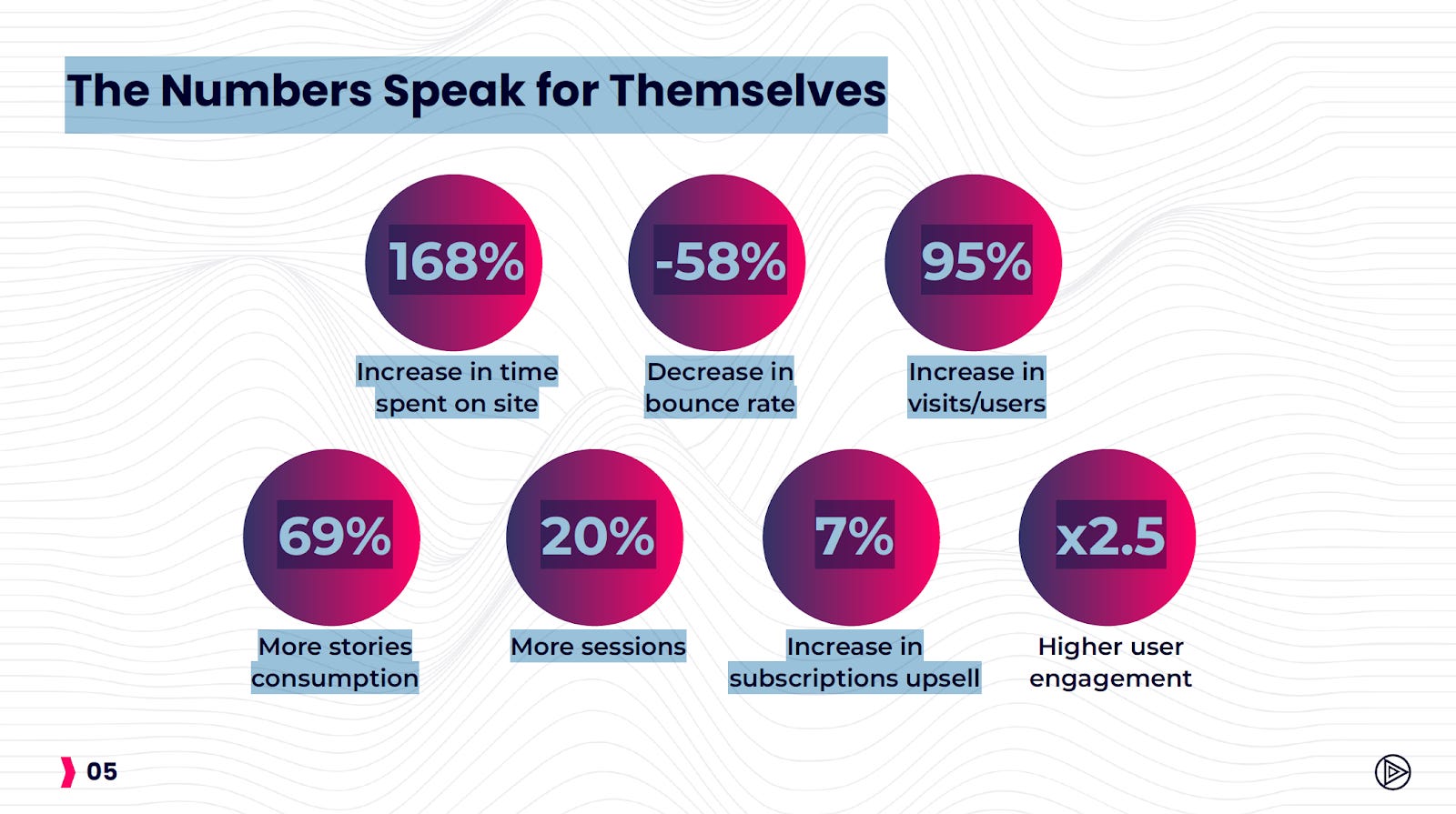
Soprattutto, non sono solo gli editori a trarre vantaggio da questa tecnologia, e tanti altri settori stanno già beneficiando di una soluzione economica, scalabile e automatizzabile per rendere ascoltabili i loro contenuti, come ad esempio il mondo della formazione. Davvero, oltre al podcast c’è molto di più, c’è un mondo di informazioni e conoscenze che aspetta solo di essere abilitato all’ascolto.
Leave a Reply